> ## Documentation Index
> Fetch the complete documentation index at: https://docs.ankra.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# AI Assistant
> AI-powered incident triangulation combining logs, metrics, manifests, and deployment context
Press `⌘+J` (Mac) or `Ctrl+J` (Windows/Linux) to open the AI Assistant from anywhere in Ankra. You can also click the chat icon in the bottom-right corner of any cluster page, or search for "AI Chat" in the Command Palette (`⌘+K`).
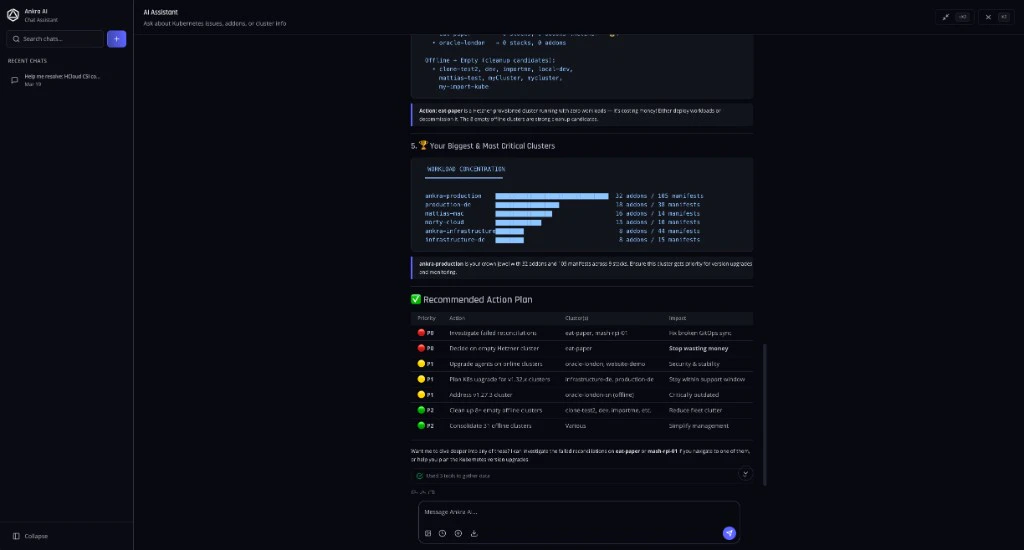 The AI Assistant combines everything Ankra knows about your cluster — logs, Kubernetes manifests, Stack deployments, resource states, and events — into a unified context for intelligent troubleshooting. This makes it exceptionally powerful for incident triangulation, connecting symptoms across multiple layers to find root causes fast.
Automatically focuses on what you're viewing — open a pod and the AI knows its logs, manifest, and status.
Correlates logs, manifests, Stack configurations, and resource states in one conversation.
Connects symptoms across pods, services, and deployments to pinpoint root causes.
Understands your CD pipeline — which Stacks deployed what, when, and with which values.
***
## Page-Aware Context
The AI Assistant automatically knows what you're looking at. When you open the chat, it focuses on your current view:
| You're Viewing | AI Automatically Knows |
| ---------------- | --------------------------------------------------------------------- |
| **A Pod** | Its logs, manifest, events, resource usage, and parent deployment |
| **A Deployment** | All replicas, rollout status, associated services, and recent changes |
| **A Stack** | Installed add-ons, Helm values, deployment history, and dependencies |
| **Logs View** | The filtered logs, error patterns, and related resources |
| **A Service** | Endpoints, selectors, connected pods, and ingress rules |
This means you don't need to explain context — just ask your question:
* *Looking at a crashing pod:* "Why is this failing?" → AI already sees the logs and events
* *Viewing a deployment:* "Scale this to 5 replicas" → AI knows which deployment
* *On the Stack page:* "Add Redis to this stack" → AI knows the current stack configuration
The AI focuses on what you focus on. Navigate to a resource before asking about it for the most relevant answers.
***
## Combined Context
What makes Ankra's AI different is the unified environment. When you ask a question, the AI has access to:
| Context Layer | What the AI Sees |
| ------------------------ | ----------------------------------------------------------- |
| **Pod Logs** | Real-time and historical container logs with error patterns |
| **Kubernetes Manifests** | Your actual deployed YAML — not just documentation |
| **Stack Deployments** | Which Helm charts were deployed, their values, and versions |
| **Resource States** | Current status, events, conditions, and health |
| **Relationships** | Service → Deployment → Pod → Container dependencies |
| **Timeline** | When deployments happened and what changed |
This combined view enables questions like:
* *"The API is returning 500 errors. Was anything deployed recently that could cause this?"*
* *"Compare the current nginx config to what was running yesterday"*
* *"Which Stack change caused the database connection failures?"*
***
## Interaction modes
The AI Assistant runs in one of three modes, which control how much it's allowed to do on its own. Pick a mode from the chat's mode selector.
Read-only. The assistant can investigate and explain but has no write tools — it will never change anything. Best for triage and learning.
The assistant can act, but every change is gated. Each write step pauses for your confirmation with a preview of what will change.
The assistant proposes a multi-step plan up front. You approve the whole plan once, then it executes the steps.
### Agentic mode: confirm each change
In **Agentic** mode, when the assistant wants to make a change it stops and shows a confirmation card describing the action, its blast radius, and — for deploys — a diff of what will change. Nothing happens until you confirm.
Because clusters change underneath you, Ankra re-checks the live state at the moment you confirm. If the cluster drifted from what the action was based on, the confirmation is blocked so you can review the change again rather than apply something stale.
### Plan mode: approve once, then execute
In **Plan** mode, the assistant breaks the work into a plan with multiple steps and shows which steps run automatically and which need confirmation. You review and approve the plan as a whole; on approval, Ankra checks that the underlying configuration hasn't drifted since the plan was drafted, then runs the steps.
Actions awaiting confirmation, plans awaiting approval, and sessions waiting on your input all surface in your [Activity & Inbox](/platform/activity-inbox), so long-running agent work doesn't get lost when you navigate away.
### Skills
The assistant draws on **skills** — curated, reusable knowledge components for specific tasks (for example, packaging an add-on or generating a CI/CD pipeline). Ankra ships built-in skills and resolves organisation-specific skills ahead of the global defaults, so the assistant applies your conventions where you've defined them.
***
## Building Stacks with AI Assistance
Describe what you want to deploy and the assistant recommends add-ons, configurations, and dependency order tailored to your cluster. The full flow is documented in [Stacks](/concepts/stacks#build-stacks-with-ai-assistance).
### Example Stack Building Prompts
* *"I need to set up a production-ready ingress with TLS"* — the assistant proposes the components (for example cert-manager and ingress-nginx), their dependency order, and starting values for your cluster.
* *"My monitoring stack is using too much memory"* — the assistant reads the actual Helm values of the deployed add-ons and suggests concrete changes such as retention windows and resource limits.
* *"Clone this stack for staging but with smaller resource requests"* — the assistant parameterises the differences with variables instead of duplicating configuration.
***
## Incident Triangulation
When something goes wrong, the AI correlates signals across your entire stack:
"Users are reporting slow API responses"
The AI checks pod logs for errors, timeouts, and latency patterns.
"I see the 'backend' Stack was updated 2 hours ago with a new database connection pool setting..."
"The postgres pod is showing high CPU and connection queue buildup..."
"The connection pool was reduced from 100 to 10 in the last Stack deployment, causing connection exhaustion under load."
### What the AI Triangulates
| Signal | How It's Used |
| ----------------------- | ------------------------------------------------------------------------ |
| **Error Logs** | Pattern matching across all pods in the affected service chain |
| **Stack History** | Recent deployments and value changes that correlate with incident timing |
| **Resource Events** | Kubernetes events showing restarts, OOMs, and scheduling failures |
| **Dependencies** | Service mesh, database connections, and external integrations |
| **Configuration Drift** | Differences between current manifests and last known good state |
***
## What Can You Ask?
* "Why is the checkout service timing out?"
* "What changed in the last hour that could cause this?"
* "Compare pod logs before and after the deployment"
* "Which upstream service is causing the 503 errors?"
* "Help me create a logging stack with Loki and Promtail"
* "What's the best way to configure ingress for multiple domains?"
* "How should I set up database backups in my Stack?"
* "Add monitoring to my existing application Stack"
* "Is my resource limit configuration correct for this workload?"
* "Why is this HPA not scaling?"
* "Explain the network policies affecting this service"
* "What secrets does this deployment need?"
* "Why did this pod get OOMKilled?"
* "What's causing intermittent connection resets?"
* "The deployment rollout is stuck — what's blocking it?"
* "Why are requests failing only to certain pod replicas?"
***
## Troubleshooting Resources
When viewing a Kubernetes resource (pod, deployment, service, etc.), you can click the **Troubleshoot** button to start an AI-assisted diagnosis:
1. Navigate to the resource in the Kubernetes browser
2. Click **Troubleshoot** in the resource details
3. The AI will analyze:
* Current resource state and events
* Related resources and dependencies
* Recent changes and logs
4. Receive actionable recommendations
***
## Chat History and Models
Conversations are saved, searchable, and can be resumed at any time — open them from the history icon in the chat header or search "Chat History" in the Command Palette (`⌘+K`). You can also switch between AI models from the chat's model selector, trading response speed for depth of analysis. Rate responses with the thumbs up/down buttons — ratings feed [AI Feedback Analytics](/platform/ai-feedback), and admins can bring their own model provider in [AI Provider settings](/platform/ai-provider).
***
## Privacy & Data
* Conversations are stored securely and associated with your account
* Cluster metadata may be shared for context (resource names, states, events)
* Sensitive data like secrets or credentials are never sent to the AI
* You can delete your chat history at any time
***
Still have questions? [Join our Slack community](https://join.slack.com/t/ankra-community/shared_invite/zt-3a5rem8f8-cUho4epX2MoLT83bFf~VSA) and we'll help out.
The AI Assistant combines everything Ankra knows about your cluster — logs, Kubernetes manifests, Stack deployments, resource states, and events — into a unified context for intelligent troubleshooting. This makes it exceptionally powerful for incident triangulation, connecting symptoms across multiple layers to find root causes fast.
Automatically focuses on what you're viewing — open a pod and the AI knows its logs, manifest, and status.
Correlates logs, manifests, Stack configurations, and resource states in one conversation.
Connects symptoms across pods, services, and deployments to pinpoint root causes.
Understands your CD pipeline — which Stacks deployed what, when, and with which values.
***
## Page-Aware Context
The AI Assistant automatically knows what you're looking at. When you open the chat, it focuses on your current view:
| You're Viewing | AI Automatically Knows |
| ---------------- | --------------------------------------------------------------------- |
| **A Pod** | Its logs, manifest, events, resource usage, and parent deployment |
| **A Deployment** | All replicas, rollout status, associated services, and recent changes |
| **A Stack** | Installed add-ons, Helm values, deployment history, and dependencies |
| **Logs View** | The filtered logs, error patterns, and related resources |
| **A Service** | Endpoints, selectors, connected pods, and ingress rules |
This means you don't need to explain context — just ask your question:
* *Looking at a crashing pod:* "Why is this failing?" → AI already sees the logs and events
* *Viewing a deployment:* "Scale this to 5 replicas" → AI knows which deployment
* *On the Stack page:* "Add Redis to this stack" → AI knows the current stack configuration
The AI focuses on what you focus on. Navigate to a resource before asking about it for the most relevant answers.
***
## Combined Context
What makes Ankra's AI different is the unified environment. When you ask a question, the AI has access to:
| Context Layer | What the AI Sees |
| ------------------------ | ----------------------------------------------------------- |
| **Pod Logs** | Real-time and historical container logs with error patterns |
| **Kubernetes Manifests** | Your actual deployed YAML — not just documentation |
| **Stack Deployments** | Which Helm charts were deployed, their values, and versions |
| **Resource States** | Current status, events, conditions, and health |
| **Relationships** | Service → Deployment → Pod → Container dependencies |
| **Timeline** | When deployments happened and what changed |
This combined view enables questions like:
* *"The API is returning 500 errors. Was anything deployed recently that could cause this?"*
* *"Compare the current nginx config to what was running yesterday"*
* *"Which Stack change caused the database connection failures?"*
***
## Interaction modes
The AI Assistant runs in one of three modes, which control how much it's allowed to do on its own. Pick a mode from the chat's mode selector.
Read-only. The assistant can investigate and explain but has no write tools — it will never change anything. Best for triage and learning.
The assistant can act, but every change is gated. Each write step pauses for your confirmation with a preview of what will change.
The assistant proposes a multi-step plan up front. You approve the whole plan once, then it executes the steps.
### Agentic mode: confirm each change
In **Agentic** mode, when the assistant wants to make a change it stops and shows a confirmation card describing the action, its blast radius, and — for deploys — a diff of what will change. Nothing happens until you confirm.
Because clusters change underneath you, Ankra re-checks the live state at the moment you confirm. If the cluster drifted from what the action was based on, the confirmation is blocked so you can review the change again rather than apply something stale.
### Plan mode: approve once, then execute
In **Plan** mode, the assistant breaks the work into a plan with multiple steps and shows which steps run automatically and which need confirmation. You review and approve the plan as a whole; on approval, Ankra checks that the underlying configuration hasn't drifted since the plan was drafted, then runs the steps.
Actions awaiting confirmation, plans awaiting approval, and sessions waiting on your input all surface in your [Activity & Inbox](/platform/activity-inbox), so long-running agent work doesn't get lost when you navigate away.
### Skills
The assistant draws on **skills** — curated, reusable knowledge components for specific tasks (for example, packaging an add-on or generating a CI/CD pipeline). Ankra ships built-in skills and resolves organisation-specific skills ahead of the global defaults, so the assistant applies your conventions where you've defined them.
***
## Building Stacks with AI Assistance
Describe what you want to deploy and the assistant recommends add-ons, configurations, and dependency order tailored to your cluster. The full flow is documented in [Stacks](/concepts/stacks#build-stacks-with-ai-assistance).
### Example Stack Building Prompts
* *"I need to set up a production-ready ingress with TLS"* — the assistant proposes the components (for example cert-manager and ingress-nginx), their dependency order, and starting values for your cluster.
* *"My monitoring stack is using too much memory"* — the assistant reads the actual Helm values of the deployed add-ons and suggests concrete changes such as retention windows and resource limits.
* *"Clone this stack for staging but with smaller resource requests"* — the assistant parameterises the differences with variables instead of duplicating configuration.
***
## Incident Triangulation
When something goes wrong, the AI correlates signals across your entire stack:
"Users are reporting slow API responses"
The AI checks pod logs for errors, timeouts, and latency patterns.
"I see the 'backend' Stack was updated 2 hours ago with a new database connection pool setting..."
"The postgres pod is showing high CPU and connection queue buildup..."
"The connection pool was reduced from 100 to 10 in the last Stack deployment, causing connection exhaustion under load."
### What the AI Triangulates
| Signal | How It's Used |
| ----------------------- | ------------------------------------------------------------------------ |
| **Error Logs** | Pattern matching across all pods in the affected service chain |
| **Stack History** | Recent deployments and value changes that correlate with incident timing |
| **Resource Events** | Kubernetes events showing restarts, OOMs, and scheduling failures |
| **Dependencies** | Service mesh, database connections, and external integrations |
| **Configuration Drift** | Differences between current manifests and last known good state |
***
## What Can You Ask?
* "Why is the checkout service timing out?"
* "What changed in the last hour that could cause this?"
* "Compare pod logs before and after the deployment"
* "Which upstream service is causing the 503 errors?"
* "Help me create a logging stack with Loki and Promtail"
* "What's the best way to configure ingress for multiple domains?"
* "How should I set up database backups in my Stack?"
* "Add monitoring to my existing application Stack"
* "Is my resource limit configuration correct for this workload?"
* "Why is this HPA not scaling?"
* "Explain the network policies affecting this service"
* "What secrets does this deployment need?"
* "Why did this pod get OOMKilled?"
* "What's causing intermittent connection resets?"
* "The deployment rollout is stuck — what's blocking it?"
* "Why are requests failing only to certain pod replicas?"
***
## Troubleshooting Resources
When viewing a Kubernetes resource (pod, deployment, service, etc.), you can click the **Troubleshoot** button to start an AI-assisted diagnosis:
1. Navigate to the resource in the Kubernetes browser
2. Click **Troubleshoot** in the resource details
3. The AI will analyze:
* Current resource state and events
* Related resources and dependencies
* Recent changes and logs
4. Receive actionable recommendations
***
## Chat History and Models
Conversations are saved, searchable, and can be resumed at any time — open them from the history icon in the chat header or search "Chat History" in the Command Palette (`⌘+K`). You can also switch between AI models from the chat's model selector, trading response speed for depth of analysis. Rate responses with the thumbs up/down buttons — ratings feed [AI Feedback Analytics](/platform/ai-feedback), and admins can bring their own model provider in [AI Provider settings](/platform/ai-provider).
***
## Privacy & Data
* Conversations are stored securely and associated with your account
* Cluster metadata may be shared for context (resource names, states, events)
* Sensitive data like secrets or credentials are never sent to the AI
* You can delete your chat history at any time
***
Still have questions? [Join our Slack community](https://join.slack.com/t/ankra-community/shared_invite/zt-3a5rem8f8-cUho4epX2MoLT83bFf~VSA) and we'll help out.